Développement
LLM
10 Octobre 2024
Maximiser l'efficacité de l'Entity Matching grâce aux LLMs

Introduction
Dans un monde où la gestion des données devient de plus en plus complexe, les entreprises doivent s'assurer de la fiabilité de leurs informations. Une grande partie des CRM et des bases de données contiennent des données obsolètes ou incorrectes, ce qui complique l'entity resolution (également appelé data matching, data linkage, ou record linkage), rendant l'enrichissement et l'actualisation des données difficiles. Cela peut non seulement introduire de nouvelles erreurs, mais aussi impacter directement les décisions stratégiques des entreprises.
Les difficultés
Lors d'un projet récent, j'ai été confronté à un double défi en cherchant à enrichir les données de plusieurs CRM avec des informations scrappées depuis des sources variées telles que LinkedIn, Crunchbase et Indeed. D'une part, il s'agissait d'extraire les données de manière fiable via du scraping, comme je l’ai récemment fait sur des portails immobiliers privés. D'autre part, il fallait s'assurer que les entités scrappées (entreprise, profil, offre d'emploi, etc.) correspondaient bien à celles déjà présentes dans le CRM.
Cela semble simple, mais les informations sont souvent formatées différemment : noms, adresses, URL. Parfois, elles sont saisies en texte libre, incomplètes, obsolètes ou divergentes, ce qui complique leur interprétation.
Entity matching vs matching traditionnel
L'entity matching diffère du matching traditionnel pour plusieurs raisons.
- Complexité des entités à comparer
Contrairement au matching classique, qui peut se limiter à la comparaison de champs spécifiques comme des identifiants ou des noms exacts, l'entity matching prend en compte des entités plus complexes, telles que des entreprises ou des profils.
- Variations et contradictions
Ces entités peuvent avoir des variations de format, des données manquantes, voire des contradictions dans les informations.
- Informations contextuelles
En plus des données de base, les entités peuvent inclure des informations contextuelles comme des descriptions, des secteurs d'activité ou des localisations, qui nécessitent une analyse plus sophistiquée, souvent basée sur des techniques de traitement du langage naturel (NLP).
- Limites des méthodes traditionnelles
Cette complexité rend les méthodes algorithmiques traditionnelles, comme les comparaisons exactes ou celles basées sur des distances (telles que Levenshtein), moins efficaces pour détecter les correspondances.
- Approche plus intelligente
L'entity matching requiert une approche plus flexible et intelligente pour analyser les données, en tenant compte des subtilités de chaque entité et en utilisant des modèles capables de gérer ces variations.
Ma solution pour ce projet
Validation manuelle des données
Avant d'automatiser le processus, nous avons passé plusieurs semaines à valider manuellement les données. Nous avons développé une interface de validation qui permettait, pour chaque type d'entité et chaque correspondance potentielle, de :
- Définir un booléen : true ou false pour indiquer s'il y avait correspondance ou non.
- Analyser les variations : identifier les différences fréquentes entre les entités scrappées et celles du CRM (noms, adresses, etc.).
- Affiner les critères de correspondance : comprendre les subtilités à prendre en compte lors de la correspondance.
Cette étape a été cruciale pour définir des règles de matching solides et minimiser les faux positifs et négatifs. Les données validées manuellement ont ensuite servi de base à la création des jeux de données d'entraînement pour le modèle.
Préparation du dataset
Une fois les données validées, j'ai structuré les informations sous forme de fichiers JSON afin de faciliter leur traitement par les modèles. Chaque fichier JSON contenait des champs clés spécifiques à chaque type d'entité. Cependant, certaines informations ont parfois été omises lorsqu'elles ne pouvaient pas être récupérées, et il y avait également des variations de format d'une entité à une autre.
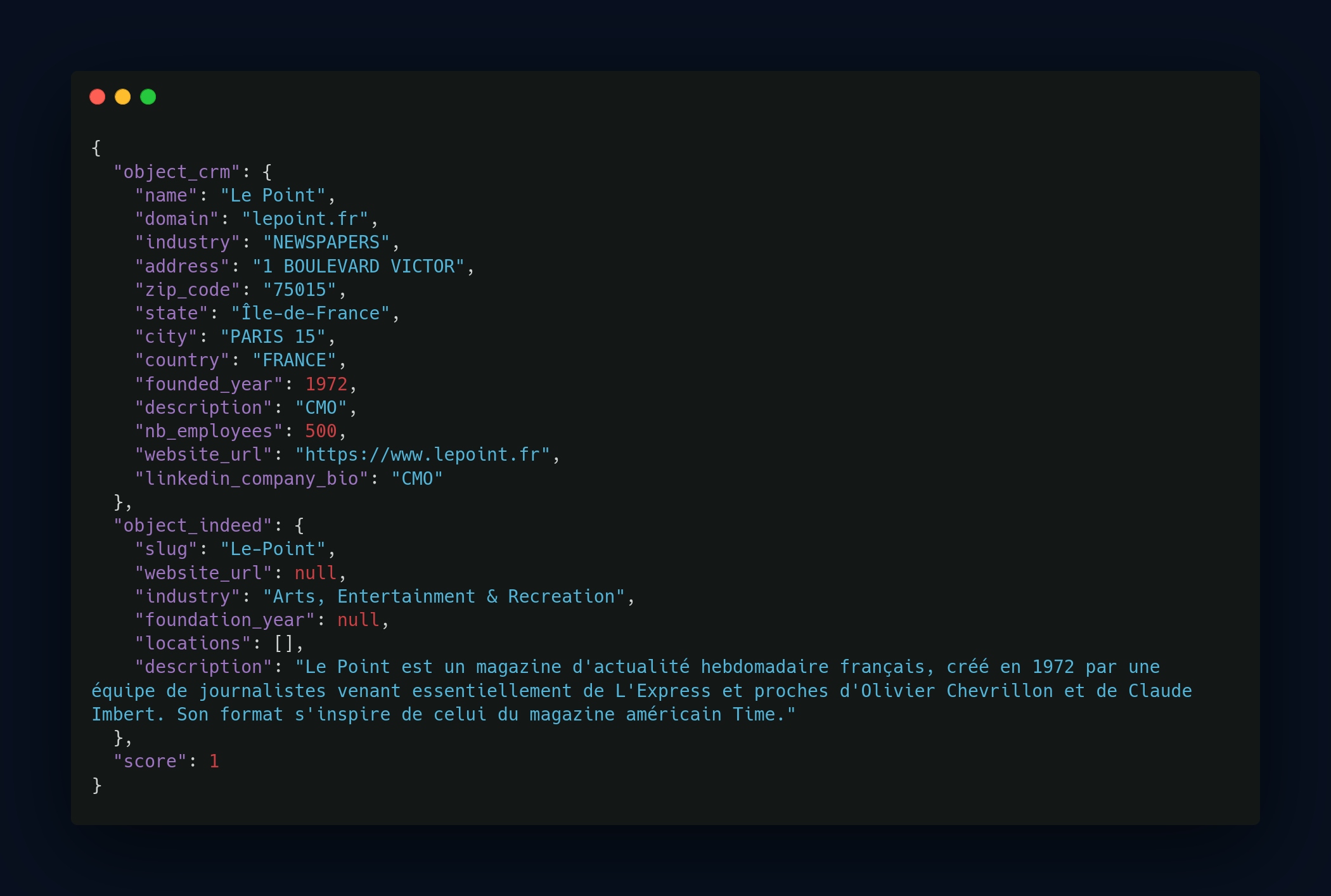
Dans cet exemple, utilisé pour l'entity resolution avec des entreprises scrappées sur Indeed, nous aurions pu nous baser uniquement sur le nom. Cependant, la probabilité que deux entreprises portent le même nom est élevée, ce qui rend cette approche sujette à des faux positifs. Nous voulions nous assurer à 100 % que les correspondances étaient exactes.
On constate que peu de champs sont disponibles à partir du scraping de la page Indeed de LePoint. L'essentiel de l'information réside dans le slug et la description.
Grâce à ces deux champs, nous sommes en mesure de déduire qu'il s'agit de la même entité, car dans le CRM, nous disposons des informations suivantes :
- Industrie
- Nom
- Date de fondation
La description sur Indeed mentionne qu'il s'agit d'un hebdomadaire fondé en 1972, ce qui confirme la correspondance. Nous attribuons donc un score de 1, indiquant que nous sommes certains qu'il s'agit de la même entité.
Ce cas ne pourrait pas être traité efficacement avec des algorithmes classiques. L'utilisation d'un LLM permet, en intégrant ce type de cas dans notre dataset, d'obtenir des résultats très précis.
Fine-tuning du modèle GPT-3.5 Turbo
Pour automatiser le scoring des correspondances, j'ai effectué un fine-tuning du modèle GPT-3.5 Turbo via l'interface d’OpenAI, en utilisant le dataset que j'avais préalablement scindé en deux : une partie pour l'entraînement et une partie pour la validation.
Cette étape consistait à fine-tuner le modèle sur une tâche spécifique à l'aide de ce dataset, afin qu'il puisse prédire avec précision la probabilité de correspondance entre deux entités.
Expérimentation avec des modèles open-source
En parallèle, j'ai également effectué des essais avec des modèles open-source, comme Mistral, en utilisant les outils de training de Hugging Face. Cela m'a permis de comparer les résultats obtenus avec ces modèles à ceux de GPT-3.5 Turbo. Bien que ces modèles aient produit des résultats intéressants, ils nécessitaient plus d'ajustements et de ressources pour atteindre le niveau de performance du modèle GPT-3.5 fine-tuné.
Cependant, l'utilisation des outils Hugging Face a ouvert des perspectives prometteuses pour des projets futurs, notamment pour ceux nécessitant plus de flexibilité et capables de traiter un grand volume de tâches.
Avec les nouveaux modèles proposés par OpenAI, tels que 4o, o1-preview et o1-mini, je pense que nous pourrions également obtenir des résultats encore meilleurs en les fine-tunant.
Utilisation du modèle
Utilisation du modèle pour le scoring de correspondances
Après le fine-tuning du modèle GPT-3.5, je l'ai intégré dans un pipeline automatisé. Le fonctionnement est simple : pour chaque entité scrappée d'une source externe (comme Crunchbase, Welcome to the Jungle, Indeed, LinkedIn, etc.), le modèle évalue sa correspondance avec une entité présente dans le CRM de l'entreprise (contact ou entreprise). Grâce à ce processus, nous avons pu automatiser ce qui prenait auparavant des heures de travail manuel.
Le modèle retournait une probabilité de correspondance sur une échelle de 0 à 1 :
- 0 : certitude de non-correspondance,
- 1 : certitude de correspondance.
Entre ces deux extrêmes, une granularité permettait d'identifier les cas incertains, nécessitant ainsi une vérification manuelle.
Exemple de scoring entre un profil LinkedIn et un contact HubSpot
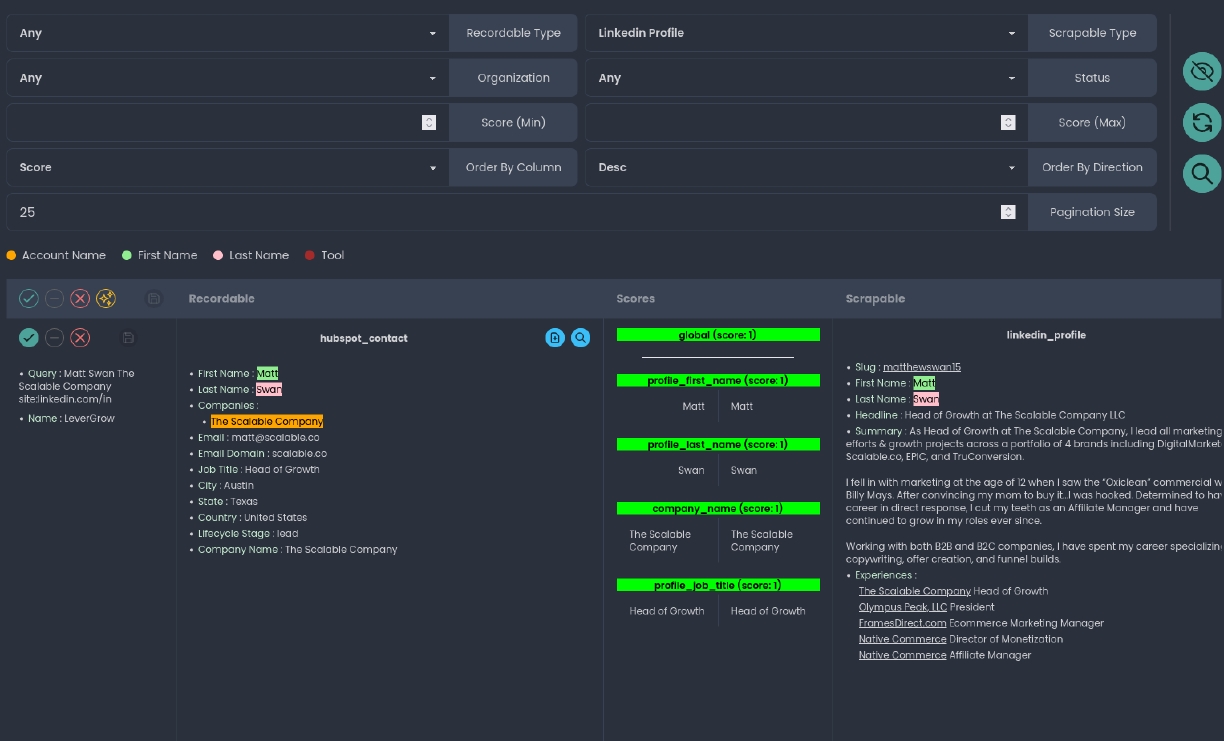
Résultats globaux
Exemples de résultats concrets
Voici quelques résultats obtenus lors de l'intégration du modèle.
- Matching avec des variations de nom :
Pour une entreprise ayant des variations de nom (par exemple, "Microsoft Corp." et "Microsost"), le modèle était capable de donner un score de 1 (100 % de certitude de correspondance) en prenant en compte des indices provenant d'autres champs.
- Matching avec des données partiellement contradictoires :
Un exemple courant est lorsque les adresses des entreprises étaient différentes, mais d'autres paramètres indiquaient une correspondance certaine. Le modèle a su identifier la correspondance avec un score de 1 en prenant en compte des éléments supplémentaires comme le secteur d'activité et la taille de l'entreprise.
Un autre exemple fréquent, surtout sur les profils, concerne les noms de jeune fille, rarement mis à jour dans les CRM. Le modèle était capable, en se basant sur d'autres champs, de gérer ce genre de cas.
- Cas incertains :
Dans certains cas, les scores étaient compris entre 0,1 et 0,9, indiquant une incertitude plus ou moins grande, notamment lorsque les informations disponibles étaient trop divergentes ou incomplètes. Par exemple, deux entreprises portant le même nom mais opérant dans des secteurs totalement différents. Dans ce cas, le modèle a signalé une incertitude, déclenchant une vérification manuelle de notre part.
Le modèle fine-tuné a atteint un taux de précision presque total pour les profils. Pour les entreprises, nous avons observé quelques prédictions incorrectes, mais je pense que cela pourrait être résolu en renforçant le dataset avec de nouveaux edge cases.
Cela a considérablement réduit le temps nécessaire pour la vérification manuelle de chaque correspondance, tout en permettant de détecter des entités qui semblaient différentes au premier abord, mais qui étaient en réalité identiques.
Leçons apprises et perspectives
L'utilisation de GPT-3.5 fine-tuné pour l'entity resolution s'est révélée très efficace, bien que dans certains cas, notamment lorsque les données étaient fortement ambiguës ou incomplètes, les résultats n'étaient pas toujours optimaux. L'expérimentation avec des modèles open-source via Hugging Face a également ouvert des perspectives intéressantes, comme la possibilité de fine-tuner des modèles open-source que l'on peut exécuter en local ou sur nos propres serveurs, ce qui réduirait considérablement les coûts à long terme.
Conclusion
L'entity resolution reste un défi de taille, notamment lorsqu'il s'agit de croiser des données provenant de multiples sources avec un CRM ou d'autres bases de données. En fine-tunant notre modèle, nous avons considérablement simplifié et optimisé ce processus.
Résultat : des heures de validation manuelle économisées et un niveau de précision dépassant celui du traitement humain, avec une réduction notable des erreurs.
À l'avenir, l'évolution des LLMs pourrait offrir des perspectives encore plus prometteuses. Les entreprises capables d'intégrer ces technologies de manière fluide auront un avantage compétitif, en optimisant leurs processus décisionnels basés sur des données fiables et actualisées.
