Web Scraping
26 Septembre 2024
J’ai scrappé 500+ projets immobiliers sur des portails privés

Introduction
J'ai scrappé plus de 500 projets immobiliers depuis des portails privés. Voici un aperçu des défis techniques rencontrés et comment ces données peuvent devenir des opportunités business pour mon client.
Les défis techniques du scraping sur des portails privés
Accès aux portails privés
Le premier défi, c'était d'obtenir les accès à ces portails. Heureusement, avec quelques bons contacts, on a pu récupérer des comptes pour 6 portails de grands promoteurs immobiliers français sans trop de complications.
Technologies vieillissantes et absence d'API
Ensuite, il fallait se confronter à la tech des portails. Vieillissants, sans API publique disponible, j'ai dû écrire des scripts un peu "maison", mais c'est aussi ce qui rend le scraping plutôt intéressant.
Sites lents et périodes de downtime
En plus de ça, les sites étaient souvent lents et passaient parfois en mode "offline" certains jours, la nuit et le week-end. C'est un peu frustrant quand tu veux avancer et que tout est à l'arrêt.
Solutions techniques apportées
Requêtes HTTP directes vs browsers headless
Je privilégie toujours les requêtes HTTP directes avant d'utiliser un navigateur headless pour le scraping.
Pourquoi ? Simplement parce que les headless browsers (comme Puppeteer ou Selenium) sont très gourmands en ressources. Ils simulent entièrement la navigation d’un utilisateur réel, ce qui est pratique mais souvent excessif pour la plupart des tâches de scraping. Dans ce cas précis, j’ai réussi à tout faire via des requêtes HTTP, en évitant ainsi la lourdeur d’un navigateur headless.
Spoofing du client pour contourner les limitations
L'une des premières étapes, c'était de structurer mes requêtes HTTP pour imiter le comportement d’un utilisateur standard sur le site. On se connecte via le navigateur, on regarde la console pour voir comment ça fonctionne (tokens, cookies, etc.), puis on reproduit tout ça dans les requêtes HTTP en injectant les bons headers comme le User-Agent et les cookies.
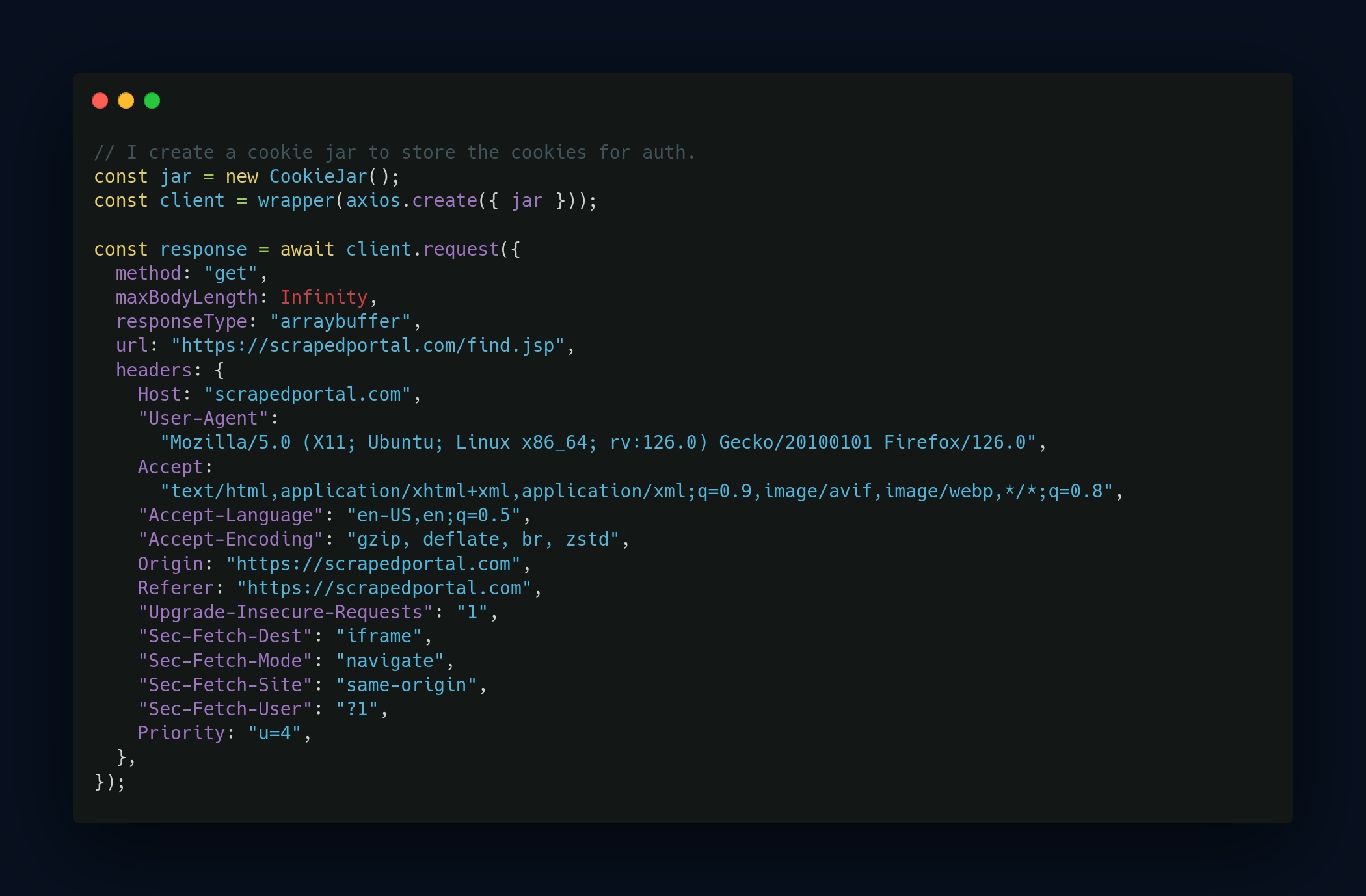
Gestion des tampons pour éviter le blocage
Étant donné qu'il s’agissait de scraping sur des portails avec login, c’était facilement détectable. Pour éviter d’attirer l’attention et de me faire bloquer, j’ai ajouté des tampons aléatoires entre chaque requête. L’idée, c’était de ne pas spammer et d'espacer les appels sur plusieurs heures. Plus discret et respectueux du rythme des serveurs, surtout quand les infrastructures sont un peu fragiles.
Utilisation de XPath pour extraire les données
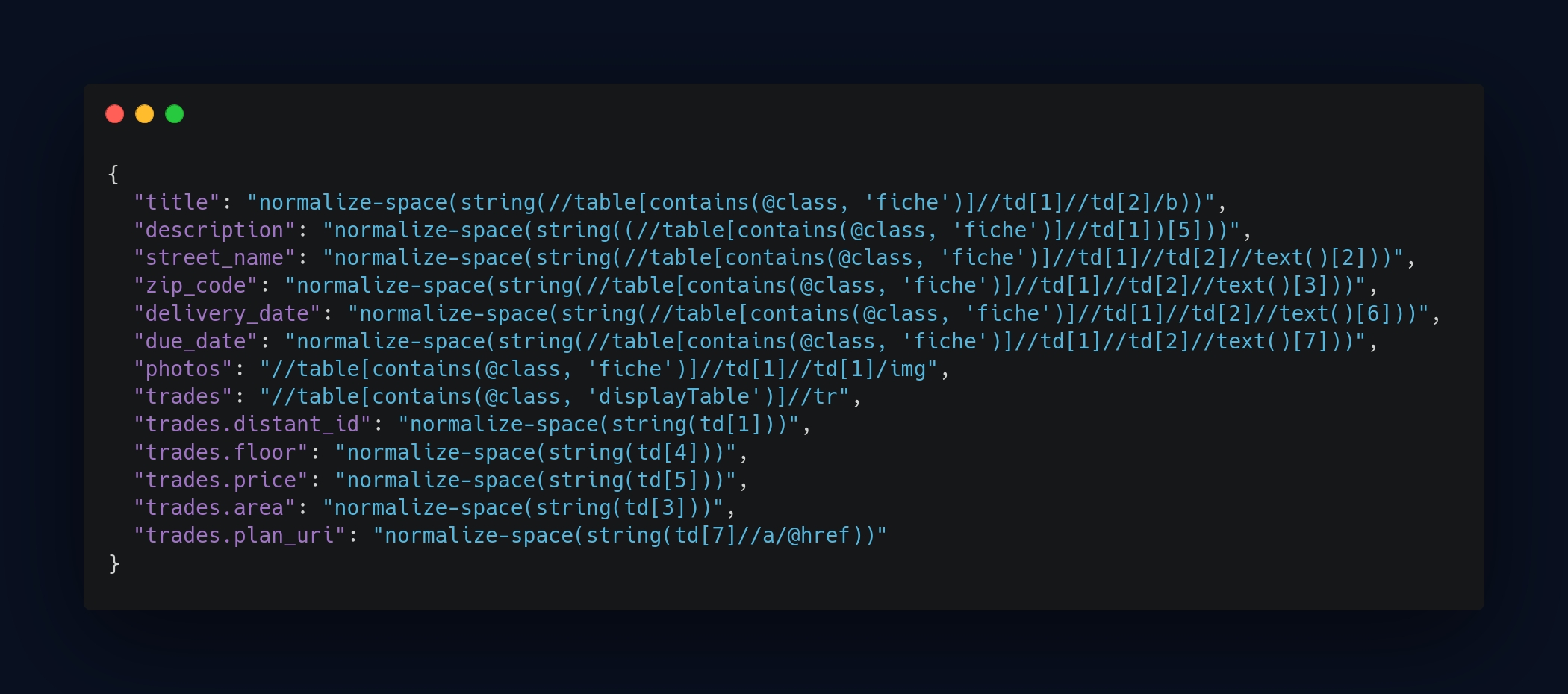
Pour certains portails (les plus modernes), j’ai eu la chance de découvrir des appels à une API externe (utilisé par le client) via la console du navigateur. Dans ces cas-là, c’était facile : il suffisait de récupérer les données directement depuis l’API, ce qui simplifiait grandement le process. Le gros du travail consistait ensuite à formater les données pour qu’elles correspondent à nos champs.
Pour les autres portails sans API, j’ai utilisé des XPath pour extraire les éléments précis de chaque page. À mes yeux, c’est la meilleure solution pour cibler avec précision les éléments d’une page web. Donc, pour chaque crawler qui n’avait pas d’API, j’ai créé un fichier XPath dédié avec tous les éléments nécessaires. Cela m'a permis d’automatiser efficacement la collecte des données sur ces pages statiques ou semi-dynamiques.
Formatage et structuration des données
C'est ici que commence le gros du travail : faire entrer les carrés dans les carrés et les triangles dans les triangles. Chaque champ doit correspondre à notre propre structure de données (typage & nom), et cela demande parfois pas mal de finesse pour tout harmoniser.
Identifier la structure des données
Dans ce genre de portails, le schéma des données est assez standard. Tu as des programmes immobiliers, et pour chaque programme, une liste de lots plus ou moins longue selon la taille du projet. Sur chaque lot ou programme, tu as des documents et des photos associés. Il était donc évident qu’il faudrait scraper plusieurs pages pour chaque programme et les relier entre elles. Cela impliquait d’identifier clairement les relations entre ces pages et de flagger les données correctement pour tout connecter à la fin.
Gestion des fichiers et photos
L’extraction des documents et des photos n’a pas posé de gros problèmes, sauf pour certains portails où les types MIME n’étaient pas correctement configurés. Par exemple, il m’est arrivé de recevoir un document PDF identifié avec un type MIME de PNG. Autant dire que c’était un peu délicat à gérer. J’ai donc dû ajouter des conditions spécifiques pour traiter ce genre de cas.
En dehors de ces particularités, l’extraction des fichiers a surtout été une question de patience. Avec des serveurs parfois lents, il fallait attendre calmement le temps de tout télécharger.
Formatage des données
La partie la plus fastidieuse, mais essentielle, c’était de restructurer les données, surtout après l’extraction via XPath. Ma méthode consiste à écrire un premier script qui récupère tout, même les détails apparemment inutiles. Ensuite, je trie, regroupe et formate chaque élément. Ça inclut le formatage des nombres, l’identification des énumérations et la correspondance des champs avec ceux de notre propre structure de données.
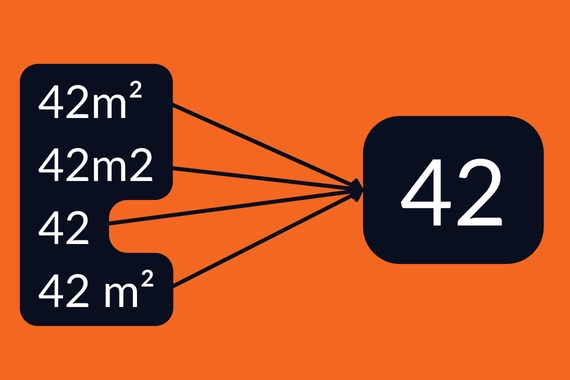
Uniformisation des champs
Un exemple simple : le formatage des surfaces des lots. Parfois, tu trouves "42m²", "42m2", d'autres fois juste "42", ou encore "42 m²" avec un espace entre les deux. Cet exemple est assez basique, mais j'ai aussi eu des cas bien plus complexes, avec beaucoup de variations de ce type à gérer.
Résultats obtenus : données exploitables et avantage compétitif
Volume de données collecté
Après avoir bouclé les 6 crawlers, j'ai scrappé plus de 1000 programmes immobiliers, avec des centaines de milliers de lots, documents et photos. Mon client a directement intégré ces données sur sa plateforme, ce qui lui permet maintenant de revendre ces informations à ses propres clients, leur offrant un accès privilégié à des données qu'ils n’auraient pas pu obtenir autrement.
Impact Business
Les données extraites, ce ne sont pas juste des chiffres ou des listings : pour les entreprises du secteur immobilier, c'est un vrai levier. Par exemple, savoir à l’avance quels projets immobiliers sont en préparation permet de se positionner avant les appels d'offres, de préparer des offres ou même de contacter directement les promoteurs pour anticiper leurs besoins. Exploiter ces infos peut représenter des millions d’euros d’opportunités. C’est un avantage concurrentiel énorme sur un marché ultra-compétitif.
Leçons apprises et bonnes pratiques
- Privilégier les requêtes HTTP directes : Quand c’est possible, évite les browsers headless. C’est plus léger et plus rapide.
- Prendre le temps de bien formater les données : C’est parfois fastidieux, mais ça rend le traitement bien plus fluide par la suite et ouvre plus de possibilités pour l’exploitation.
Conclusion : le scraping, un avantage concurrentiel majeur
Chaque mission de scraping a ses spécificités et ses défis, mais lorsqu'elle est bien exécutée, elle permet d’accéder à des informations cruciales pour les entreprises. Le scraping n’est pas juste une extraction de données : c’est un levier stratégique pour générer de nouvelles opportunités commerciales et se positionner sur des marchés ultra-compétitifs.
