Development
LLM
10 October 2024
Maximizing the Efficiency of Entity Matching with LLMs

Introduction
In a world where data management is becoming increasingly complex, companies must ensure the reliability of their information. A large portion of CRMs and databases contain outdated or incorrect data, complicating entity resolution (also known as data matching, data linkage, or record linkage), making data enrichment and updating difficult. This can not only introduce new errors but also directly impact strategic business decisions.
Challenges
During a recent project, I faced a dual challenge in attempting to enrich data from multiple CRMs with information scrapped from various sources such as LinkedIn, Crunchbase, and Indeed. On one hand, it was about reliably extracting data through scraping, as I recently did on private real estate portals. On the other hand, it was necessary to ensure that the scrapped entities (company, profile, job offer, etc.) matched the ones already present in the CRM.
It sounds simple, but the information is often formatted differently: names, addresses, URLs. Sometimes they are entered as free text, incomplete, outdated, or divergent, complicating their interpretation.
Entity Matching vs Traditional Matching
Entity matching differs from traditional matching for several reasons.
- Complexity of Entities to Compare
Unlike traditional matching, which may be limited to comparing specific fields like identifiers or exact names, entity matching considers more complex entities, such as companies or profiles.
- Variations and Contradictions
These entities may have format variations, missing data, or even contradictory information.
- Contextual Information
In addition to basic data, entities may include contextual information such as descriptions, business sectors, or locations, which require more sophisticated analysis, often based on natural language processing (NLP) techniques.
- Limitations of Traditional Methods
This complexity makes traditional algorithmic methods, such as exact comparisons or those based on distances (such as Levenshtein), less effective in detecting matches.
- Smarter Approach
Entity matching requires a more flexible and intelligent approach to analyze the data, considering the subtleties of each entity and using models capable of handling these variations.
My solution for this project
Manual Data Validation
Before automating the process, we spent several weeks manually validating the data. We developed a validation interface that allowed, for each type of entity and each potential match, to:
- Define a Boolean: true or false to indicate if there was a match or not.
- Analyze variations: identify frequent differences between scraped entities and those in the CRM (names, addresses, etc.).
- Refine matching criteria: understand the nuances to consider when matching.
This step was crucial to define solid matching rules and minimize false positives and negatives. The manually validated data then served as the basis for creating training datasets for the model.
Dataset Preparation
Once the data was validated, I structured the information in JSON files to facilitate processing by the models. Each JSON file contained specific key fields for each type of entity. However, some information was sometimes omitted when it could not be retrieved, and there were also format variations from one entity to another.
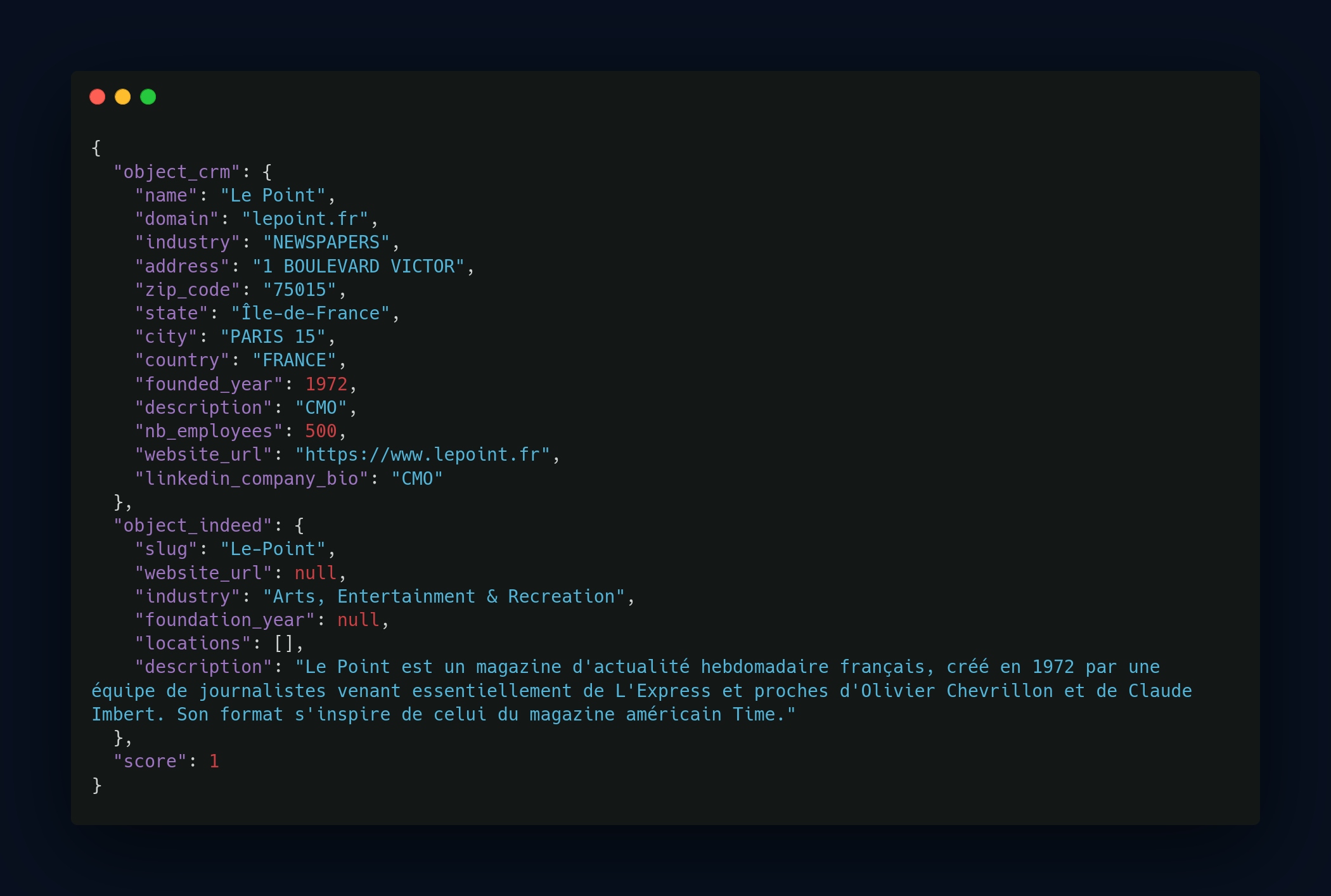
In this example, used for entity resolution with companies scraped from Indeed, we could have relied solely on the name. However, the probability that two companies have the same name is high, making this approach prone to false positives. We wanted to ensure 100% accuracy in matches.
It is noted that few fields are available from scraping the Indeed page of LePoint. The main information resides in the slug and the description.
Thanks to these two fields, we can deduce that it is the same entity, as in the CRM we have the following information:
- Industry
- Name
- Foundation date
The description on Indeed mentions that it is a weekly magazine founded in 1972, which confirms the match. We therefore assign a score of 1, indicating that we are certain it is the same entity.
This case could not be effectively handled with traditional algorithms. Using LLMs allows, by integrating this type of case into our dataset, to achieve very precise results.
GPT-3.5 Turbo Model Fine-tuning
To automate the matching scoring, I performed a fine-tuning of the GPT-3.5 Turbo model via the OpenAI interface, using the dataset I previously split into two: one part for training and one part for validation.
This step consisted of fine-tuning the model on a specific task using this dataset, so that it could accurately predict the probability of a match between two entities.
Experimentation with Open-Source Models
In parallel, I also conducted trials with open-source models, like Mistral, using Hugging Face training tools. This allowed me to compare the results obtained with these models to those of GPT-3.5 Turbo. Although these models produced interesting results, they required more adjustments and resources to reach the performance level of the fine-tuned GPT-3.5 model.
However, using Hugging Face tools has opened promising opportunities for future projects, particularly for those requiring more flexibility and capable of handling a large volume of tasks.
With the new models proposed by OpenAI, such as 4o, o1-preview, and o1-mini, I believe we could also achieve even better results by fine-tuning them.
Model Usage
Using the Model for Matching Scoring
After fine-tuning the GPT-3.5 model, I integrated it into an automated pipeline. The process is simple: for each entity scraped from an external source (such as Crunchbase, Welcome to the Jungle, Indeed, LinkedIn, etc.), the model evaluates its match with an entity present in the company's CRM (contact or company). Through this process, we have been able to automate what used to take hours of manual work.
The model returned a matching probability on a scale from 0 to 1:
- 0: certainty of non-match,
- 1: certainty of match.
Between these two extremes, granularity allowed the identification of uncertain cases, thus requiring manual verification.
Example of Scoring Between a LinkedIn Profile and a HubSpot Contact
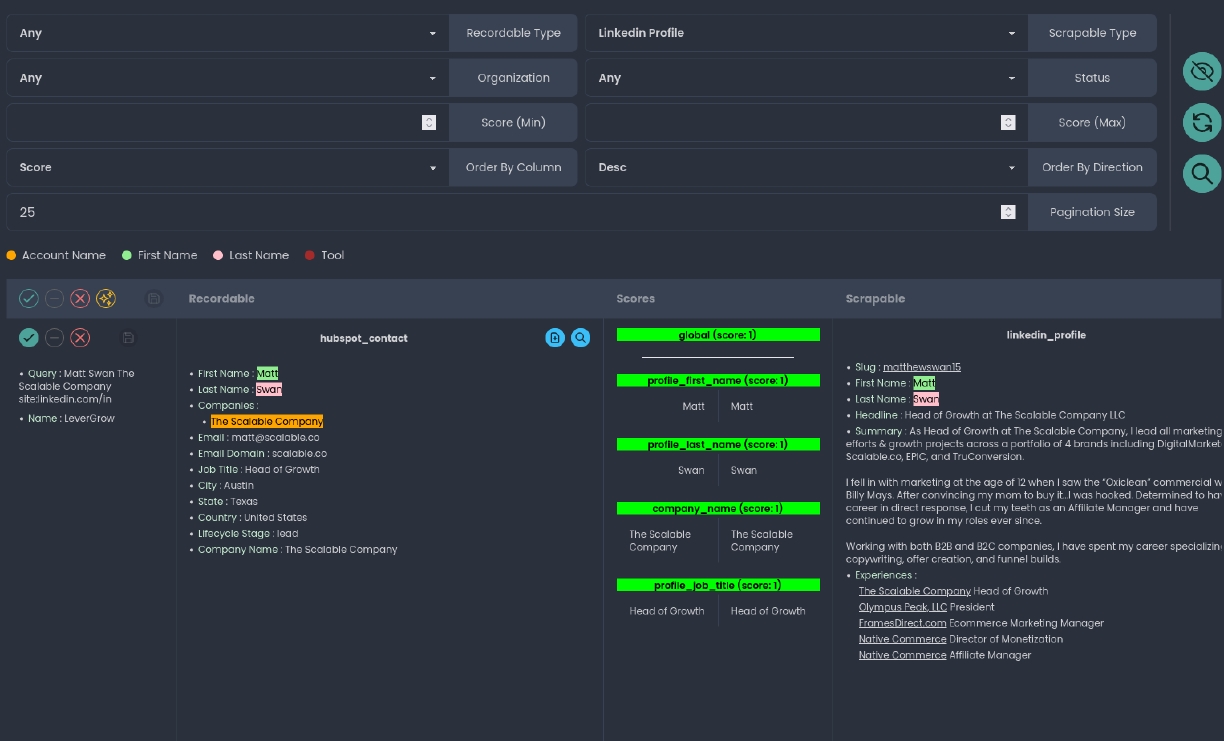
Global Results
Examples of Concrete Results
Here are some results obtained during the integration of the model.
- Matching with Name Variations:
For a company with name variations (e.g., "Microsoft Corp." and "Microsost"), the model was able to give a score of 1 (100% certainty of match) by considering clues from other fields.
- Matching with Partially Contradictory Data:
A common example is when the companies' addresses were different, but other parameters indicated a certain match. The model managed to identify the match with a score of 1 by considering additional elements like the sector and the company's size.
Another frequent example, especially on profiles, concerns maiden names, rarely updated in CRMs. The model was able, based on other fields, to manage this type of case.
- Uncertain Cases:
In some cases, the scores ranged between 0.1 and 0.9, indicating varying degrees of uncertainty, especially when the available information was too conflicting or incomplete. For example, two companies with the same name but operating in entirely different sectors. In this case, the model flagged uncertainty, prompting a manual check from us.
The fine-tuned model achieved an almost total accuracy rate for profiles. For companies, we observed some incorrect predictions, but I think this could be resolved by enhancing the dataset with new edge cases.
This significantly reduced the time needed for manual verification of each match while allowing the detection of entities that initially seemed different but were actually identical.
Lessons Learned and Perspectives
The use of fine-tuned GPT-3.5 for entity resolution has proven to be very effective, although in some cases, especially when the data were highly ambiguous or incomplete, the results were not always optimal. Experimentation with open-source models via Hugging Face has also opened up interesting perspectives, such as the possibility of fine-tuning open-source models that can be run locally or on our own servers, which would significantly reduce long-term costs.
Conclusion
Entity resolution remains a significant challenge, especially when it comes to merging data from multiple sources with a CRM or other databases. By fine-tuning our model, we have greatly simplified and optimized this process.
Result: hours of manual validation saved and a level of accuracy surpassing that of human processing, with a notable reduction in errors.
In the future, advancements in LLMs might offer even more promising prospects. Companies that can seamlessly integrate these technologies will have a competitive advantage by optimizing their decision-making processes based on reliable and up-to-date data.
