Web Scraping
24 September 2024
I scraped 500+ real estate projects from private portals

Introduction
I scraped over 500 real estate projects from private portals. Here’s an overview of the technical challenges encountered and how this data can turn into business opportunities for my client.
The technical challenges of scraping private portals
Access to private portals
The first challenge was getting access to these portals. Luckily, with a few good contacts, we managed to get accounts for 6 major French real estate developers’ portals without too much trouble.
Outdated technologies and lack of API
Next, we had to deal with the tech behind these portals. Old systems, no public API available, so I had to write some "homemade" scripts, but that’s also what makes scraping quite interesting.
Slow sites and periods of downtime
On top of that, the sites were often slow and would go "offline" at certain times, like nights and weekends. It’s a bit frustrating when you want to make progress and everything is at a standstill.
Technical solutions applied
HTTP requests vs. headless browsers
I always prefer direct HTTP requests over using a headless browser for scraping.
Why? Simply because headless browsers (like Puppeteer or Selenium) are very resource-intensive. They fully simulate a real user’s navigation, which is useful but often overkill for most scraping tasks. In this case, I managed to do everything with HTTP requests, avoiding the heaviness of a headless browser.
Spoofing the client to bypass limitations
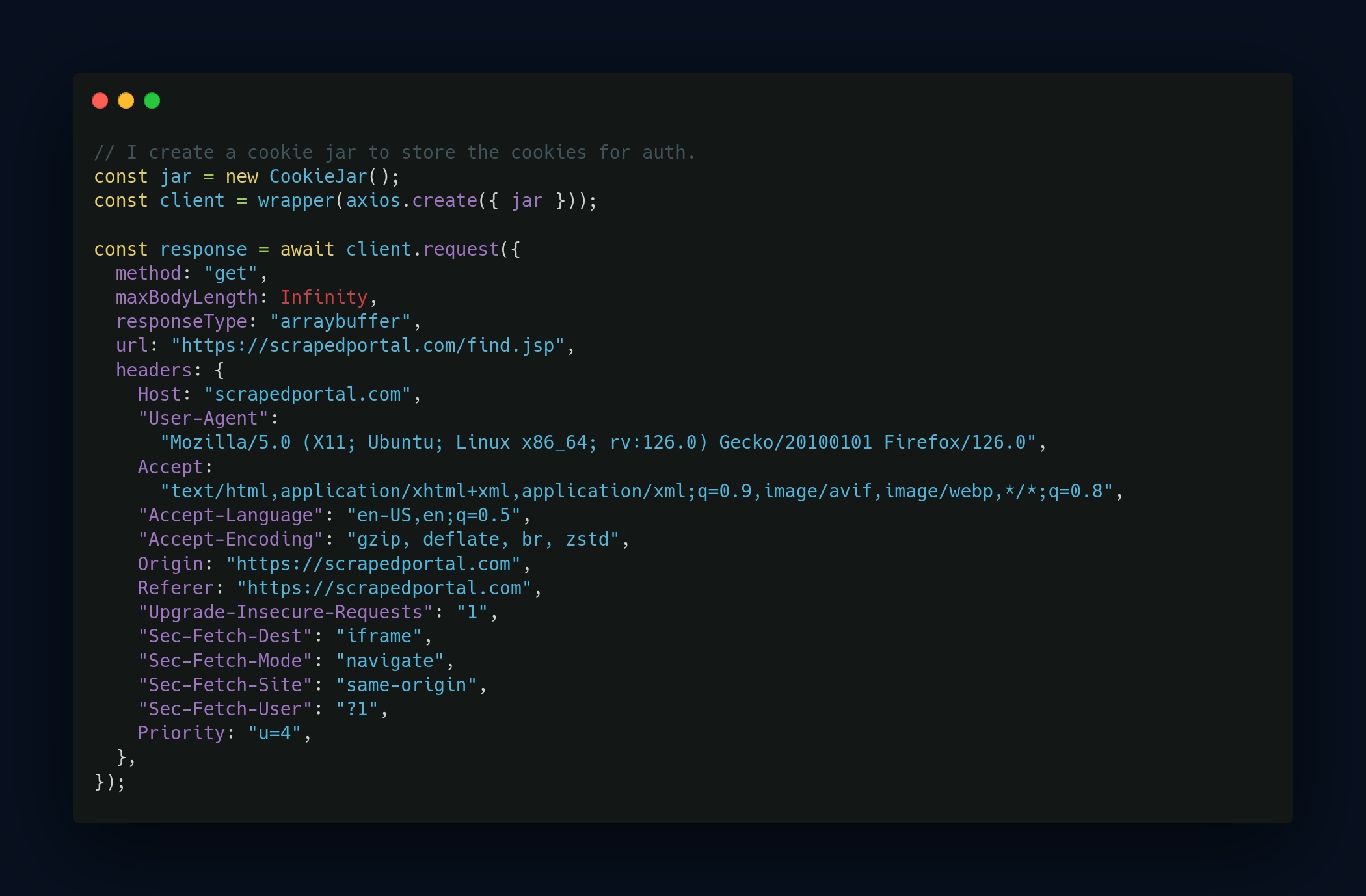
One of the first steps was to structure my HTTP requests to mimic the behavior of a regular user on the site. You connect via the browser, check the console to see how it works (tokens, cookies, etc.), then reproduce all of that in the HTTP requests, injecting the right headers like User-Agent and cookies.
Adding delays to avoid detection
Since this was scraping from portals with login, it was easy to detect. To avoid drawing attention and getting blocked, I added random delays between each request. The idea was not to spam and to space the requests over several hours. This made the scraping more discreet and respectful of the server’s rhythm, especially when the infrastructure was a bit fragile.
Using XPath to extract data
For some portals (the more modern ones), I found external API calls (used by the client) via the browser’s console. In those cases, it was easy: I just retrieved the data directly from the API, which greatly simplified the process. The main work then was formatting the data to match our fields.
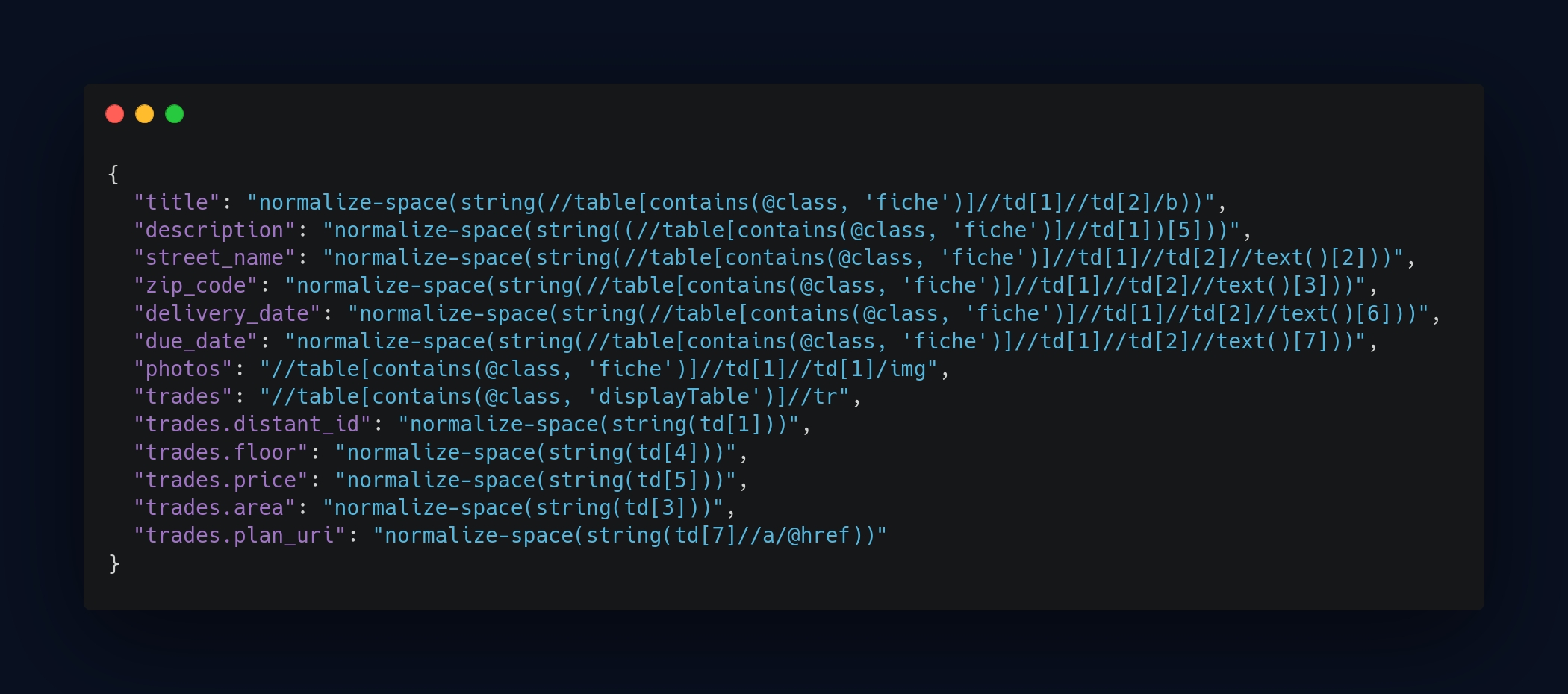
For the other portals without an API, I used XPath to extract the specific elements from each page. In my opinion, this is the best solution to precisely target elements on a webpage. So, for each crawler that didn’t have an API, I created a dedicated XPath file with all the necessary elements. This allowed me to efficiently automate the collection of data from these static or semi-dynamic pages.
Data formatting and structuring
This is where the bulk of the work begins: fitting the squares into the squares and the triangles into the triangles. Each field must match our own data structure (type & name), and that sometimes requires quite a bit of finesse to get everything aligned.
Identifying the data structure
In this type of portal, the data structure is fairly standard. You have real estate programs, and for each program, a list of lots that varies in length depending on the project size. Each lot or program has associated documents and photos. It was obvious I’d have to scrape multiple pages for each program and link them together. This meant clearly identifying the relationships between these pages and flagging the data correctly to connect everything in the end.
Handling files and photos
Extracting documents and photos wasn’t a big problem, except for some portals where MIME types weren’t properly configured. For example, I received a PDF file that was identified as a PNG MIME type. Needless to say, that was a bit tricky to handle. I had to add specific conditions to process these types of cases.
Other than that, file extraction was mostly a matter of patience. With slow servers, it was necessary to wait calmly for everything to download.
Data formatting
The most tedious but essential part was restructuring the data, especially after extraction via XPath. My method is to write a first script that retrieves everything possible, even the seemingly unnecessary details. Once I have all the data, I sort through it, group it, and format each element. This includes formatting numbers, identifying enumerations, and matching the fields with our own data structure.
Field uniformity
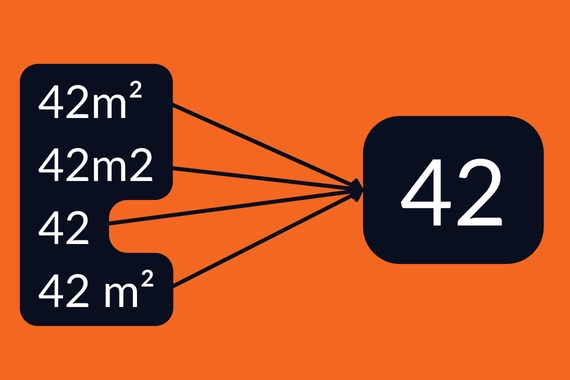
A simple example: formatting the lot surface areas. Sometimes you find "42m²", other times "42m2", and sometimes just "42", or even "42 m²" with a space. This example is basic, but I also encountered much more complex cases, with many variations like this that had to be managed.
Results: actionable data and competitive advantage
Volume of data collected
In the end, after running the 6 crawlers, I scraped over 500 real estate programs, with hundreds of thousands of lots, documents, and photos. My client directly integrated this data into their platform, which now allows them to resell this information to their own clients, giving them privileged access to data they wouldn’t have been able to obtain otherwise.
Business impact
The data extracted isn’t just a bunch of numbers or listings: for companies in the real estate sector, it’s a real lever. For example, knowing in advance which real estate projects are in the pipeline allows you to position yourself before tenders, prepare bids, or even contact developers directly to anticipate their needs. Exploiting this information can represent millions of euros in opportunities. It’s a huge competitive advantage in an ultra-competitive market.
Lessons learned and best practices
- Favor HTTP requests: When possible, avoid headless browsers. It’s lighter and faster.
- Take the time to properly format the data: It’s sometimes tedious, but it makes data processing much smoother later on and opens up more possibilities for exploitation.
Conclusion: scraping, a major competitive advantage
Each scraping project has its own specificities and challenges, but when done right, it allows access to crucial information for businesses. Scraping isn’t just about extracting data: it’s a strategic lever for generating new business opportunities and positioning yourself in competitive markets.
